目的
使用logstash 进行项目的日志的收集; logstash 好比是一个io的读写 , 需要一个源 和目的地 当然还需要一个过滤器;
思路:
第一步,logstash 使用项目产生的日志就是我们要读取的源 然后采用redis作为我们的目的地
第二步,logstash redis作为源 , 然后 目的地是我们的elasticsearch 的内存
思考一个问题: 为什么不直接采用 项目日志作为源, elasticsearch 内存作为目的地直接将我们的日志生保存到elasticsearch 呢?
第一步
启动我们的logstash : D:\dev\logstash-6.6.1>.\bin\logstash -f config\test.conf
config 的配置如下:
input {
file {
#path 是启动项目的日志的目录
path => "D:/dev/workspace-sts-3.9.0.RELEASE/spring-boot-dubbo-zookeeper/log/provider.log"
type => "provider-log"
start_position => "beginning"
stat_interval => "2"
}
}
output {
#type是自定义的名称, 配置redis的host,port,密码
if [type] == "provider-log" {
redis {
data_type => "list"
key => "provider-log"
host => "10.1.51.96"
port => "6379"
db => "0"
password => "redis"
}}
}
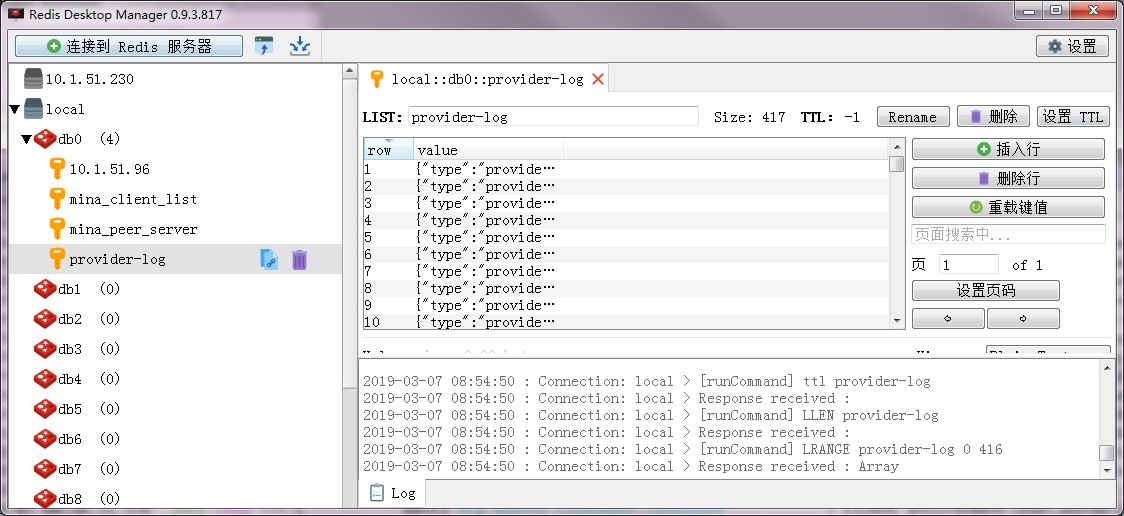
观察我们的redis, 我们发现我们的redis 的key为type , 保存起来的是一个list集合
第二步
启动我们的logstash : D:\dev\logstash-6.6.1>.\bin\logstash -f config\readTest.conf
启动elasticsearch
config 的配置如下:
input {
redis {
data_type => "list"
key => "provider-log"
host => "10.1.51.96"
port => "6379"
db => "0"
password => "redis"
codec => "json"
}
}
output {
if [type] == "provider-log" {
elasticsearch {
hosts => ["10.1.51.96:9200"]
index => "provider-log-%{+YYYY.MM.dd}"
}}
}
启动elasticsearch-head , 观察我们的内存里面是否有日志的index
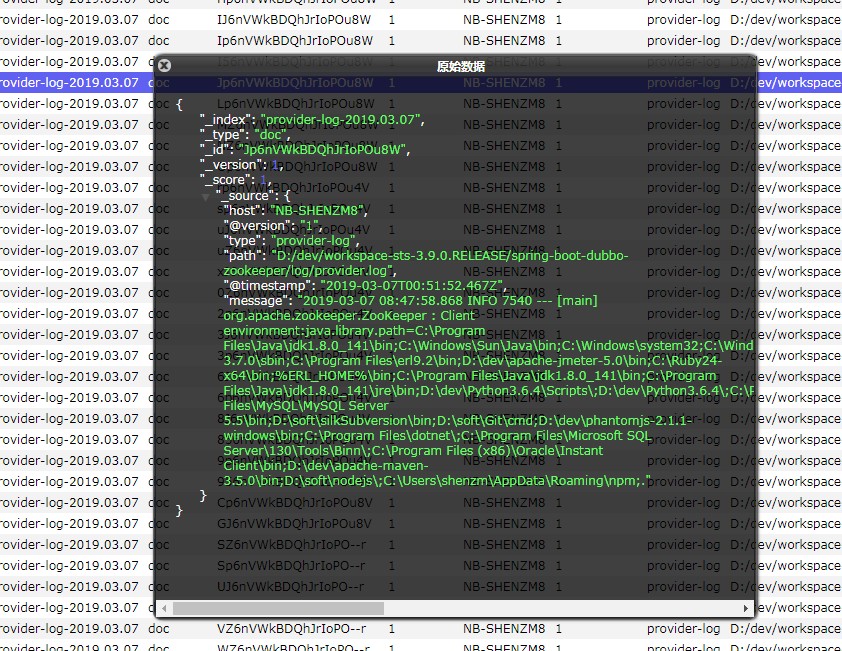
ok 完美结束~~
如果采用直接从日志读取, 保存到elastic会怎么样呢? 配置如下: 启动后保存到elastic的日志里面
然后会发现message字段,不是我们想要的日志的输出··· ()
input {
file {
path => "D:/dev/workspace-sts-3.9.0.RELEASE/spring-boot-dubbo-zookeeper/log/provider.log"
type => "provider-log"
start_position => "beginning"
stat_interval => "2"
}
}
output {
if [type] == "provider-log" {
elasticsearch {
hosts => ["10.1.51.96:9200"]
index => "provider-log-%{+YYYY.MM.dd}"
}}
}
reference
http://www.cnblogs.com/can-H/articles/7872052.html
